朴素贝叶斯实现文本数据的分类与分析
关于实现朴素贝叶斯算法的原理,参考于此。
利用朴素贝叶斯算法实现对文本的数据挖掘,主要包括:
- 语料库的构建,主要包括利用爬虫收集Web文档等。
- 语料库的数据预处理,包括文档建模,如去噪,分词,建立数据字典。
- 自行实现朴素贝叶斯,训练文本分类器。
- 对测试集的文本进行分类
- 对测试集的分类结果利用正确率和召回率进行分析评价。
数据预处理
- 爬虫技术:
依赖python requests库:requests可以支持HTTP特性,是python中最常用的http客户端库。
从环球网、新浪网、搜狐网等大型门户网站上爬取得到的原始数据如下图所示。文本数据所属类别分别包括:动漫、汽车、娱乐、财经、游戏、健康、历史、军事、运动、科技,共十大类。总体数据量共一百万条。

- 对爬取到的数据进行分词
使用jieba分词库将所有句子分成词组的形式,再通过停用词表过滤过滤掉所有的停用词和字符。得到如下文本数据如下图所示。
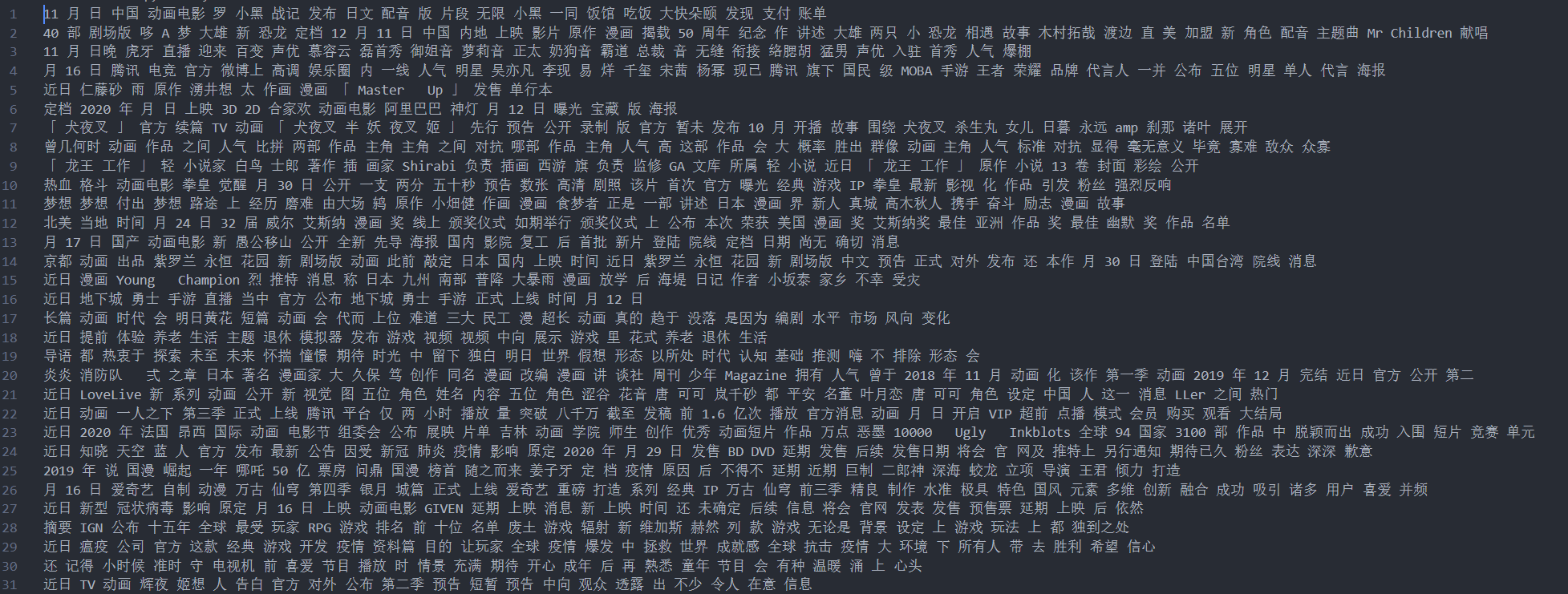
- 生成词袋
再通过使用TF_IDF技术,贝叶斯算法需要保留按照分值排序前40000个词汇,获得经过TF_IDF处理后的词汇表。

实验结果
对于50w条测试集的测试结果展示:
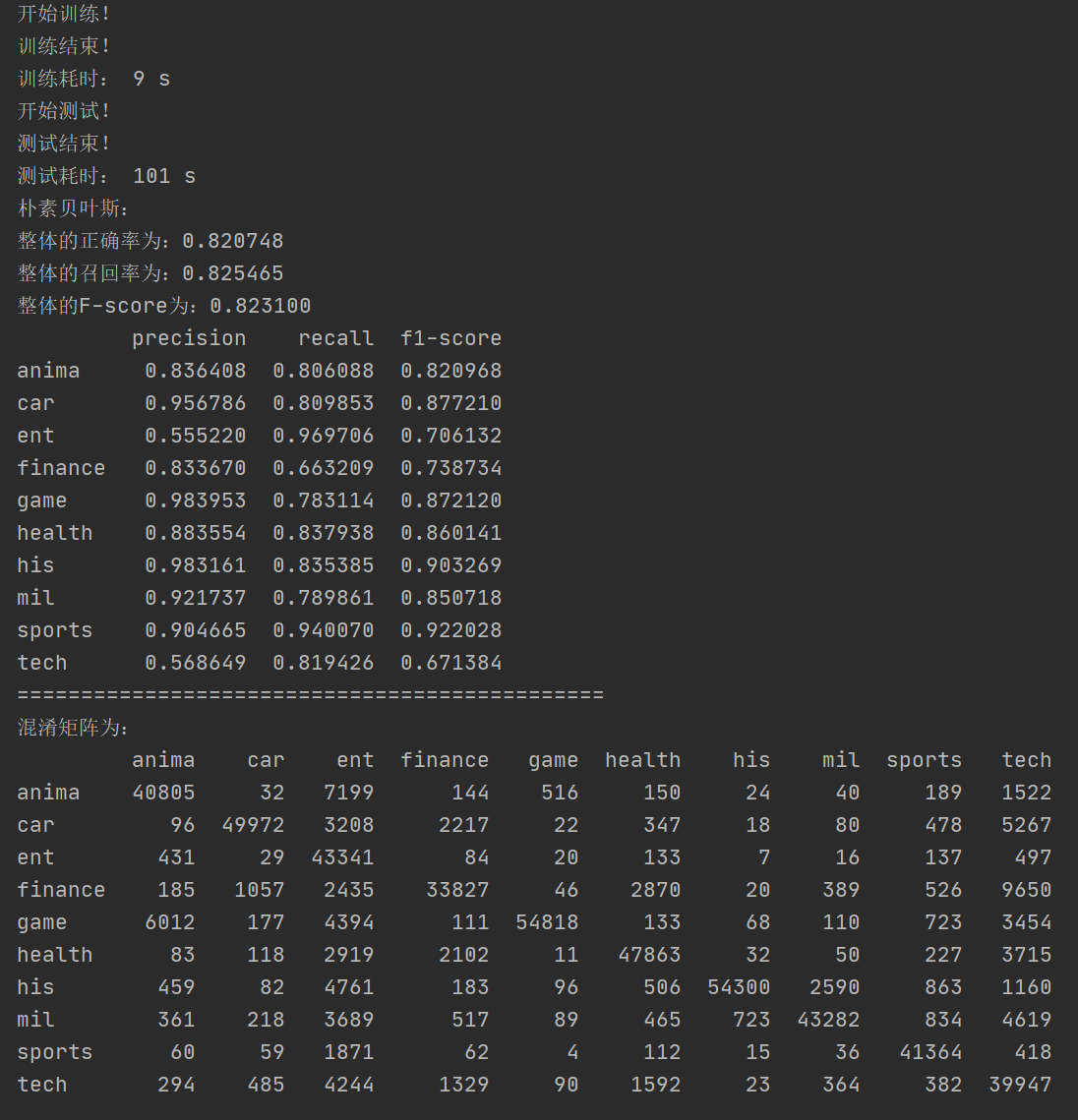
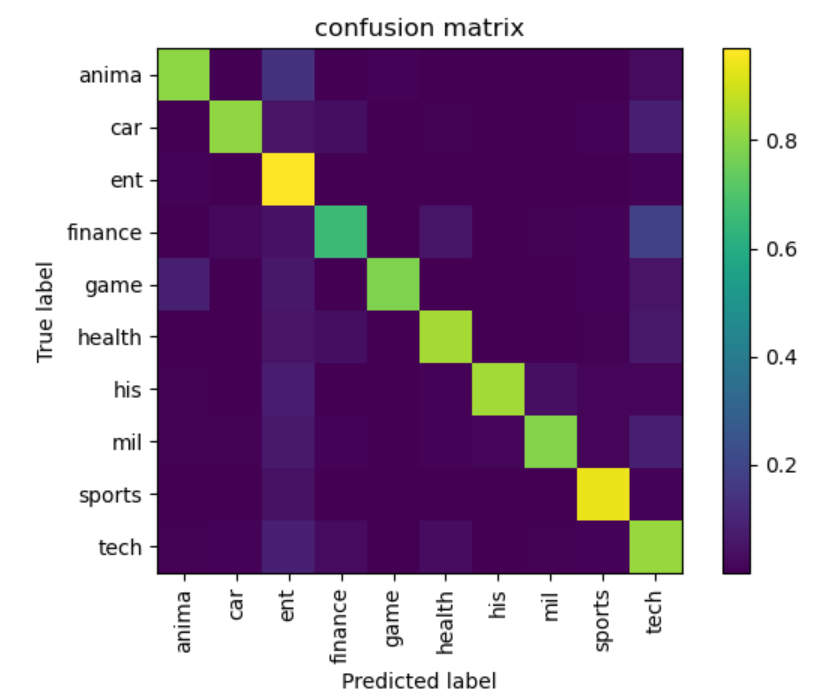
程序使用数据集以及具体实现代码,点击这里
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!